
AI - Extract Text from Images
This AI-powered tool leverages Tesseract OCR to extract text from images, whether printed or handwritten. It's designed to digitize content from scanned documents, books, or handwritten notes, making them editable and searchable. With practical applications ranging from academic use to everyday utility, users can convert notes, product labels, or even text from street signs into usable digital content. The tool also serves as a foundation for translation and accessibility features when integrated with other NLP tools, supporting language conversion and broader access to textual information.
Technologies Used
- Python
- Tesseract OCR
- Pytesseract
- PIL (Python Imaging Library) / Pillow
Built using Python, this solution combines the efficiency of Pytesseract (a wrapper for Tesseract OCR) with the versatility of Pillow for image processing. The setup is streamlined to run in environments like Google Colab, allowing users to upload images, process them with OCR, and download the extracted text in just a few steps. Ideal for students, researchers, and professionals, this project simplifies the transition from physical to digital text, enhancing productivity and access to information.
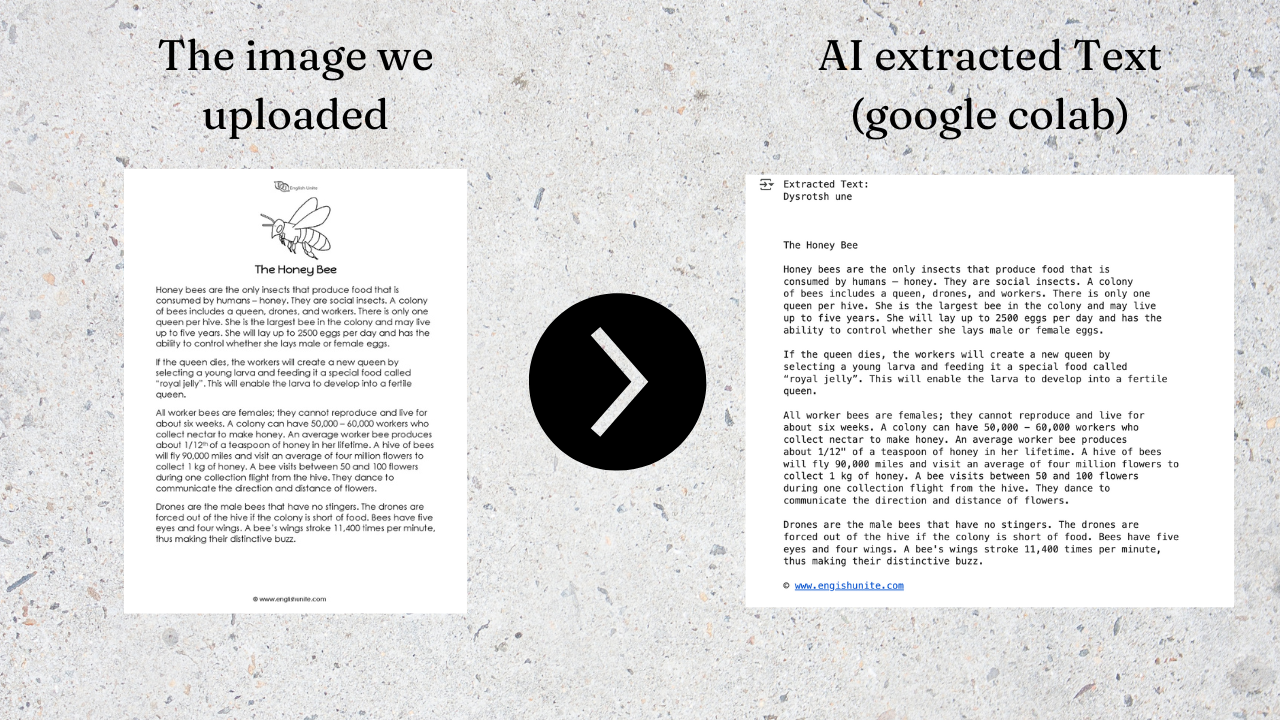
Why Build This AI?
The AI has several real-world uses, such as:
- Digitizing Printed or Handwritten Documents: Convert scanned documents, printed books, or handwritten notes into editable and searchable digital text.
- Translation and Accessibility: Extract text from images for instant language translation (using other NLP tools).
- Extract Info from Photos & Screenshots: Get text from street signs, product labels, documents in photos.
- Educational Tools: Students can upload handwritten or textbook notes to convert them into searchable digital documents.
Let's Build It
Environment Setup for OCR using Tesseract and Pytesseract
This code sets up everything needed to run OCR in Python:
- Imports subprocess and sys: To run shell commands and install packages.
install_package(): Installs Python libraries using pip.install_tesseract(): Installs the Tesseract OCR engine using apt-get (for Linux/Colab).- Tries to import pytesseract: And installs it if not found.
import subprocess
import sys
# Install necessary packages
def install_package(package):
subprocess.check_call([sys.executable, "-m", "pip", "install", package])
def install_tesseract():
subprocess.run(["apt-get", "update"])
subprocess.run(["apt-get", "install", "-y", "tesseract-ocr"])
try:
import pytesseract
except ImportError:
install_package("pytesseract")
import pytesseract
Image Upload and Preparation for OCR
This section installs the Tesseract OCR engine, prompts the user to upload an image, and prepares the image for text extraction:
install_tesseract(): Ensures Tesseract is installed.files.upload(): Opens a file picker in Google Colab to upload an image.- The uploaded image is loaded using
PIL.Image.open(): Prepares the image for OCR processing.
# Install Tesseract OCR
install_tesseract()
from PIL import Image
from google.colab import files
import os
# Upload image
print("Upload an image containing text")
uploaded = files.upload()
image_filename = list(uploaded.keys())[0]
# Open image
image = Image.open(image_filename)
Performing OCR and Saving Extracted Text
This section uses Tesseract to extract text from the uploaded image and handles output:
- Set the path to the Tesseract executable: Ensures the OCR engine is correctly referenced.
image_to_string(): Extracts text from the image using OCR.- The extracted text is saved to a
.txtfile: For future use or reference. - Text is printed on the screen and made available for download using
files.download(): Enables users to save the result locally.
# Set Tesseract path
pytesseract.pytesseract.tesseract_cmd = "/usr/bin/tesseract"
# Perform OCR
extracted_text = pytesseract.image_to_string(image)
# Save extracted text to a file
text_filename = "extracted_text.txt"
with open(text_filename, "w") as text_file:
text_file.write(extracted_text)
# Display extracted text
print("Extracted Text:")
print(extracted_text)
# Download extracted text file
files.download(text_filename)

